

目前市场上的HIL视频注入板卡分两种:
HDMI方案:图像走显卡的HDMI/DP接口到板卡,主要用在HIL-Sim上
PCIe方案:图像走服务器PCIe到板卡,HIL-Sim和HIL-Replay都在用
HDMI方案

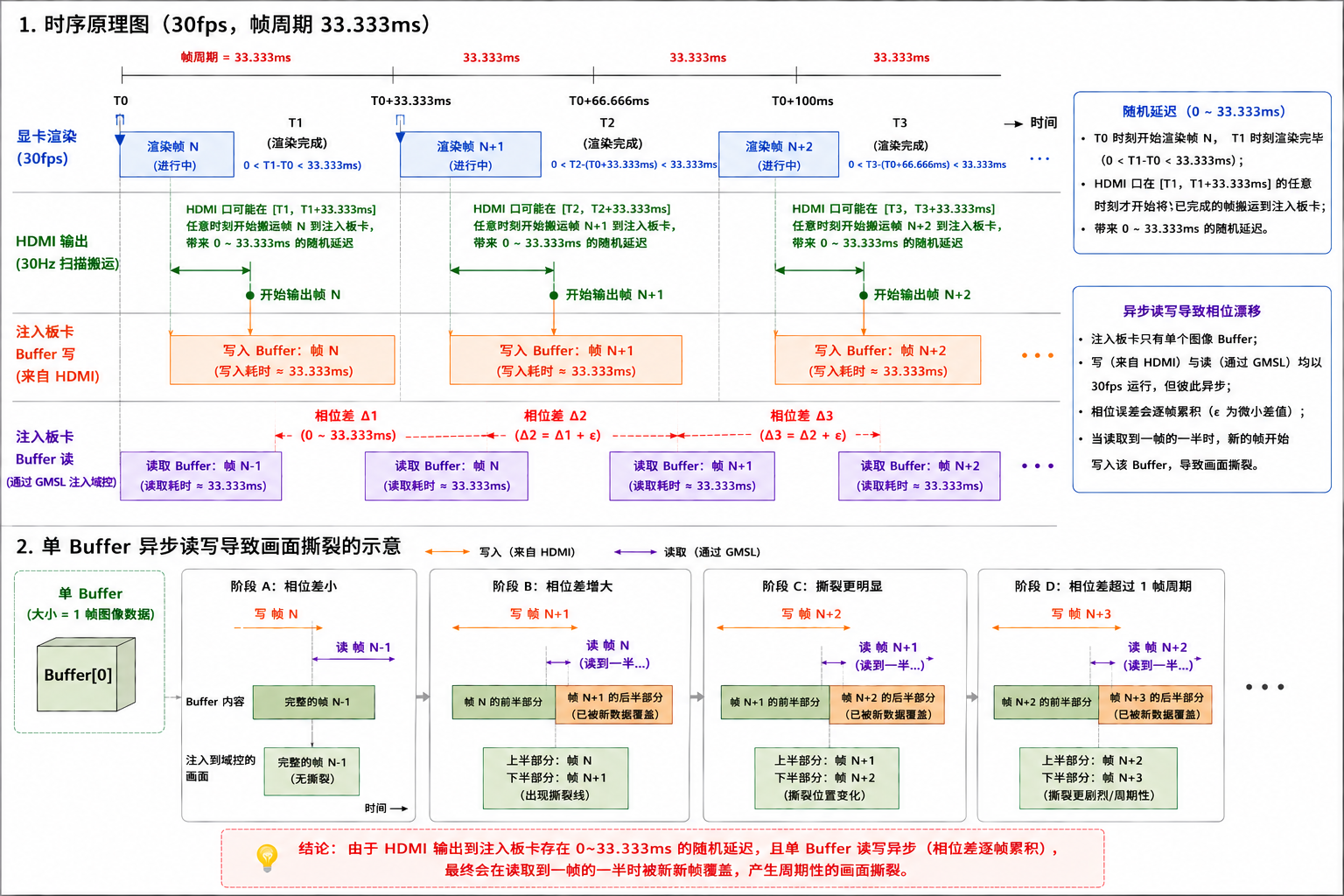
HDMI方案主要用在HIL-Sim中,图像在显卡渲染好之后,直接通过显卡的HDMI/DP口输出到板卡,这么做有个明显的好处:完全不占用服务器PCIe或内存带宽,这样就算配置稍低的服务器也能hold住(节约服务器成本)。但是有明显的坏处,那就是HDMI接口是异步的(我们没法控制HDMI什么时候开始传输一帧图像),这就会导致一个帧周期内的随机延迟和图像撕裂。
这里举个例子,假如ECU域控视频是30fps的,我们渲染的帧率也是30fps,显卡里配置的HDMI帧率30Hz的,一帧周期是33.333ms。渲染仿真器在显卡中于T0时刻开始渲染一帧图形,在T1时刻渲染完毕(0<T1-T0<33.333ms)。显卡HDMI口可能在[T1, T1+33.333ms]区间内的任意时间才开始把图形搬运到注入板卡中,带来了一个0到33.333ms的随机延迟。而且注入板卡为了尽快让图像注入ECU域控,通常只会留单个图像buffer(也用多buffer方案,只是实现起来很复杂)。来自显卡HDMI线的30fps的图像往该buffer写的同时,还会以30fps的速度读该buffer并通过GMSL注入域控。然而该buffer的读写虽然都是30fps,但是彼此是异步的,会慢慢积累相位误差,这就会导致读buffer才读到某帧一半的时候,新的一帧就写入buffer了,导致周期性的画面撕裂。
这里有同学就要举手了,说“好像Nvidia有个技术叫Quadro Sync II的板卡可以解决这个问题!”
对,也不全对:
首先Quadro Sync技术只支持Nvidia的quadro专业显卡,比如RTX A4000(专业显卡渲染能力差又死贵),而跑HIL-Sim恰恰需要渲染能力强的消费级显卡。
其次,Quadro Sync是做的多路显卡的HDMI输出相位同步的,只是把原来的多路HDMI独立的随机延迟变成了一样的随机延迟,画面撕裂依旧。
当然了,你说我做个专门的板卡把Quadro Sync的同步信号读到服务器里,然后让渲染图像的相位跟踪Quadro Sync相位。然后调整渲染时机,保证在每帧T1时刻渲染好的时候,恰好HDMI开始读这一帧。可以,虽然这么做很麻烦就是了。
总之,HDMI方案在随机延迟和画面撕裂这块,优化起来很麻烦。
PCIe方案

PCIe方案可以用在HIL-Replay或HIL-Sim中:图像在显卡解码(HIL-Replay)或渲染(HIL-Sim)好之后,先下载到主机内存,然后再走PCIe传到板卡。在PCIe方案中,不会存在随机的延迟,渲染仿真器通过跟踪ECU的frame-trigger/frame-sync相位,在一帧渲染好之后可以立刻走PCIe给到注入板卡,理论上可以做到几ms的延迟。注入板卡也可以很方便的用多buffer方案解决画面撕裂问题。
由于图像要先下载到主机内存,需要服务器采购更多更好的内存。但是在内存暴涨的2026年做出这个决定应该很艰难,比如我25年5月jd以500块一片买的SK DDR5RECC 4800MHz内存,现在26年5月价格已经涨到3200块一片。有同学会问为啥图像一定要先下载到主机内存,图像直接从显卡走PCIe传输到注入板卡不行么?可以的,这个技术叫GPUDirect,同样需要Nvidia的专业显卡才有支持哦。
其实大家也不要被这个内存流量给吓到了,我们假设有8路4K(3840*2160分辨率)的30fps视频需要注入,那么raw视频流量为:3840长 x 2160宽 x 一个像素2字节 x 30fps x 8路 = 3.98GB/s,注意读写总流量为7.96GB/s,这7.96GB/s会分配到N个内存通道上分流。如果是8通道内存,那么一个内存通道只有1GB/s的流量,轻轻松松。需要注意的是,对于HIL-Replay而言内存基本用来存取raw视频不做他用,所以内存性能刚好满足需求即可。但是对于HIL-Sim而言,跑N路渲染仿真器是很依赖高频多核CPU和良好内存速度的,因此需要内存尽可能的有裕量,即内存速度越快越好、插得越多越好(笑)。
结尾
欢迎了解卡朗仿真科技的12路GMSL2视频PCIe注入板卡CH2,我们还提供HIL-Replay台架CHR,另外基于Carla的HIL-Sim台架CHS也在密集开发中,尽请期待。